
Videosorveglianza IA 100 Locale: Home Assistant, Mac Mini M4 e Qwen2.5-VL (Addio Cloud!)
di Vincenzo Caputo
24 Febbraio 2026
Home Assistant

Se c'è un tema che ha acceso le discussioni qui sul blog ultimamente, è senza dubbio quello della Privacy.
Qualche tempo fa, vi avevo mostrato come integrare l'intelligenza artificiale di Google Gemini per analizzare i fotogrammi delle telecamere di sicurezza. Una soluzione potente, certo, ma che ha sollevato una domanda legittima da parte di molti di voi: "Vincenzo, ma io non voglio inviare le foto del mio giardino o di casa mia ai server di Google! Non si può fare in locale?"
La risposta è sì. E le prestazioni sono sbalorditive.
In una guida precedente, avevamo già visto come installare Ollama su un Mac Mini M4 per portare l'IA locale dentro Home Assistant. In quell'occasione, però, ci eravamo limitati al controllo domotico e alle domande testuali. Oggi facciamo il salto di qualità definitivo: diamo la vista alla nostra casa, mantenendo ogni singolo byte strettamente confinato tra le nostre mura.
Ecco come ho trasformato il mio Mac Mini M4 nel cervello visivo locale di Home Assistant.
1. La scelta del modello: Il trionfo di Qwen2.5-VL
Prima di arrivare al risultato perfetto, ho testato decine di modelli di visione (LLaVA, Bakllava e varianti varie). Il risultato? Spesso deludente. Allucinazioni, oggetti inventati o tempi di elaborazione biblici.
Finché non sono approdato a Qwen2.5-VL (nello specifico la versione a 7 miliardi di parametri, qwen2.5vl:7b). Questo modello è un cecchino: riconosce persone, veicoli e animali con una precisione chirurgica e ha una capacità di sintesi in italiano perfetta per le notifiche domotiche.
1.5 L'Installazione di Qwen2.5-VL (Il Motore Visivo) e LLM Vision
Dando per scontato che abbiate già installato il "motore" base di Ollama sul vostro Mac Mini (se vi manca questo pezzo, rimando alla mia guida precedente), il passaggio successivo è scaricare fisicamente il "cervello visivo" che analizzerà le nostre telecamere.
Aprite il Terminale di macOS e digitate questo singolo comando:
ollama pull qwen2.5vl:7b
(Nota: a seconda degli aggiornamenti della repository ufficiale di Ollama, il tag esatto potrebbe essere anche qwen2.5-vl. Se il primo vi dà errore, usate il secondo).
Cosa succede ora? Il Mac inizierà a scaricare il modello direttamente nella sua memoria locale. Parliamo di un file di circa 4.5 - 5 GB, quindi mettetevi comodi e aspettate che la barra di avanzamento del terminale arrivi al 100%. Una volta finito, il modello sarà vostro, residente sul vostro SSD. Niente più cloud, niente abbonamenti, niente foto inviate all'esterno.
Il ponte verso Home Assistant: LLM Vision Ora che l'IA risiede sul Mac, Home Assistant deve sapere come parlarci. Per farlo, usiamo un'integrazione fantastica chiamata LLM Vision (scaricabile gratuitamente tramite HACS).
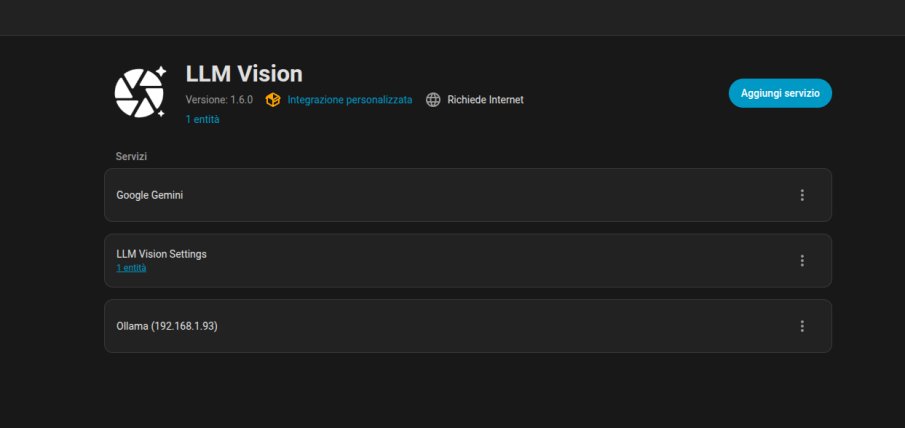
Ecco i passaggi esatti per configurarli insieme:
In Home Assistant, andate su Impostazioni > Dispositivi e Servizi.
Cliccate su Aggiungi Integrazione e cercate LLM Vision.
Vi chiederà quale Provider usare: selezionate Ollama. Se non ve lo chiede subito potrete aggiungere successivamente un servizio cliccando su Aggiungi Servizio
![Videosorveglianza IA 100 Locale: Home Assistant, Mac Mini M4 e Qwen2.5-VL (Addio Cloud!)]()
Alla voce Host/URL, inserite l'indirizzo IP locale del vostro Mac Mini seguito dalla porta standard di Ollama 11434
Dentro default model inserite esattamente quello che avete scaricato sul Mac Mini. Selezionate il vostro fiammante qwen2.5vl:7b appena scaricato.
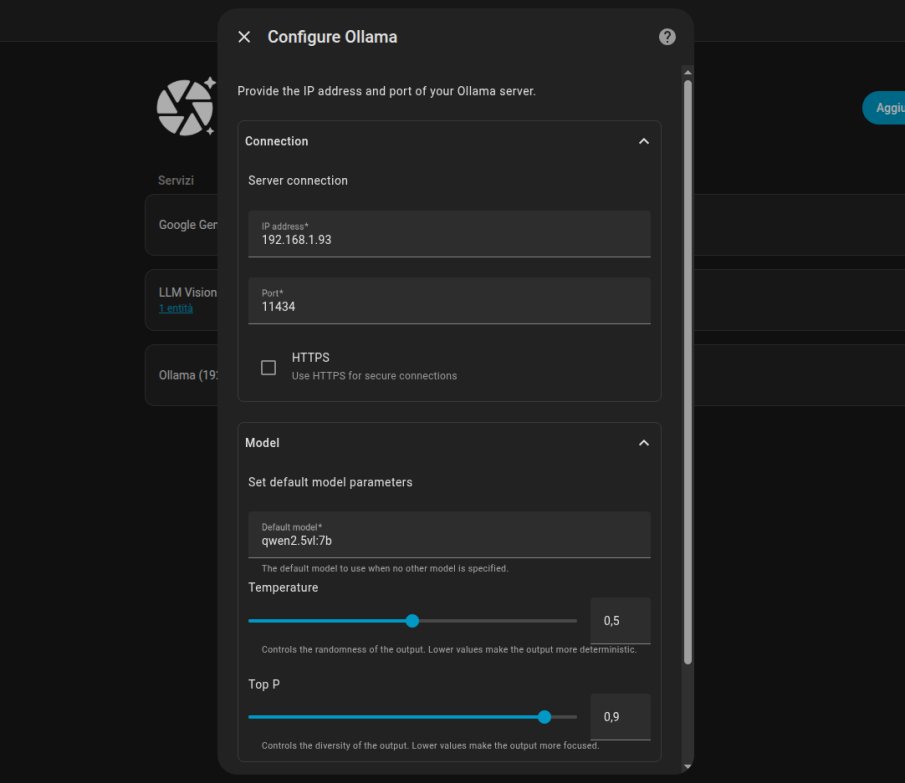
Fatto. I due sistemi ora comunicano perfettamente. Ma attenzione, qui entra in gioco un dettaglio tecnico fondamentale che fa la differenza tra un sistema lento e uno fulmineo...
2. Il problema del "Cold Start" e il Dittatore della Memoria (macOS)
Qui arriva la parte interessante, lo scoglio tecnico su cui molti si infrangono quando cercano di usare l'IA per la videosorveglianza in tempo reale.
I nuovi Mac con Apple Silicon (M1/M2/M3/M4) hanno una gestione della memoria unificata estremamente aggressiva. Di default, se Ollama non viene interrogato per 5 minuti, scarica brutalmente i 5GB del modello dalla RAM veloce. Il risultato? Quando la vostra telecamera rileva un movimento in giardino, il Mac impiegherà anche 15-20 secondi per ricaricare il modello da zero (il cosiddetto Cold Start). Un'eternità che manda in Timeout le automazioni di Home Assistant, restituendo notifiche vuote.
Il primo passo (La forzatura): Dobbiamo dire a Ollama di non scaricare mai il modello. Per farlo in modo pulito ed invisibile, aprite il Terminale del Mac Mini e digitate crontab -e.
Incollate questa riga (se usate l'editor di default, premete i per inserire il testo, poi Esc, digitate :wq e date Invio):
@reboot sleep 60 && curl http://localhost:11434/api/generate -d '{"model": "qwen2.5vl:7b", "keep_alive": -1}' >/dev/null 2>&1
Cosa fa questo comando? Ad ogni avvio del Mac, attende 60 secondi (per far avviare i servizi) e poi inietta in background una chiamata API che ordina a Ollama di caricare Qwen2.5-VL e tenerlo in vita per un tempo infinito (keep_alive: -1).
Il secondo passo (La realtà del Paging di macOS):
A questo punto potreste pensare: "Ottimo, il modello è in RAM, la risposta sarà sempre nell'ordine dei millisecondi!". Sbagliato. Anche se abbiamo imposto a Ollama di non chiudere il processo, il kernel di macOS fa di testa sua. Se per un paio d'ore non passa nessuno in giardino (o dove è posizionata la telecamera), il sistema operativo nota che quei 5GB di RAM non vengono "toccati". Per ottimizzare le risorse, macOS li comprime o li sposta silenziosamente sul disco SSD (il famoso file di Swap).
Quando finalmente il sensore scatta, avviene un "Page Fault": la CPU richiede quei dati, macOS capisce che servono di nuovo e deve andarli a ripescare dal disco per rimetterli nella RAM unificata. Grazie alla velocità pazzesca degli SSD dei Mac Mini M4, questa operazione non impiega più 15 secondi, ma genera comunque un ritardo fisiologico che varia dai 2 ai 6 secondi.
In ambito domotico, aspettare 6 secondi davanti a uno schermo nero per sapere chi è entrato dal cancello è fastidioso. Ed è qui che la nostra architettura fa la differenza.
3. L'Automazione "A prova di bomba" (Feedback Asincrono e Retry Loop)
Per gestire in modo elegante questo ritardo fisiologico di macOS (e salvarci dai rari timeout di rete), ho progettato un'automazione che sfrutta il Feedback Asincrono, una tecnica da veri sistemi Enterprise.
Invece di lasciare l'utente in attesa del risultato dell'IA, inganniamo l'attesa gestendo due notifiche con lo stesso identico tag:
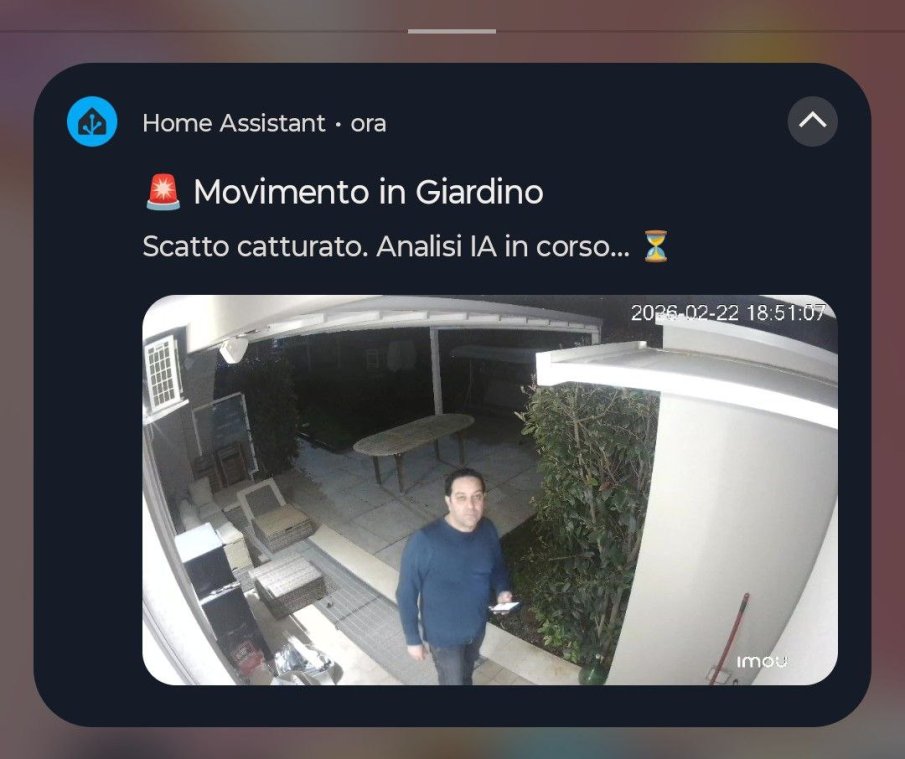
Notifica Istantanea (0 secondi): L'automazione invia immediatamente una notifica al telefono con lo scatto fotografico e la scritta "Analisi IA locale in corso... ⏳". Così sapete all'istante che c'è movimento e avete già la foto sotto gli occhi.
![Videosorveglianza IA 100 Locale: Home Assistant, Mac Mini M4 e Qwen2.5-VL (Addio Cloud!)]()
Ciclo di Retry: Nel frattempo, Home Assistant interroga il Mac Mini. Se il Mac sta "svegliando" la memoria e va in timeout al primo colpo, lo script non va in errore, ma aspetta 3 secondi e riprova.
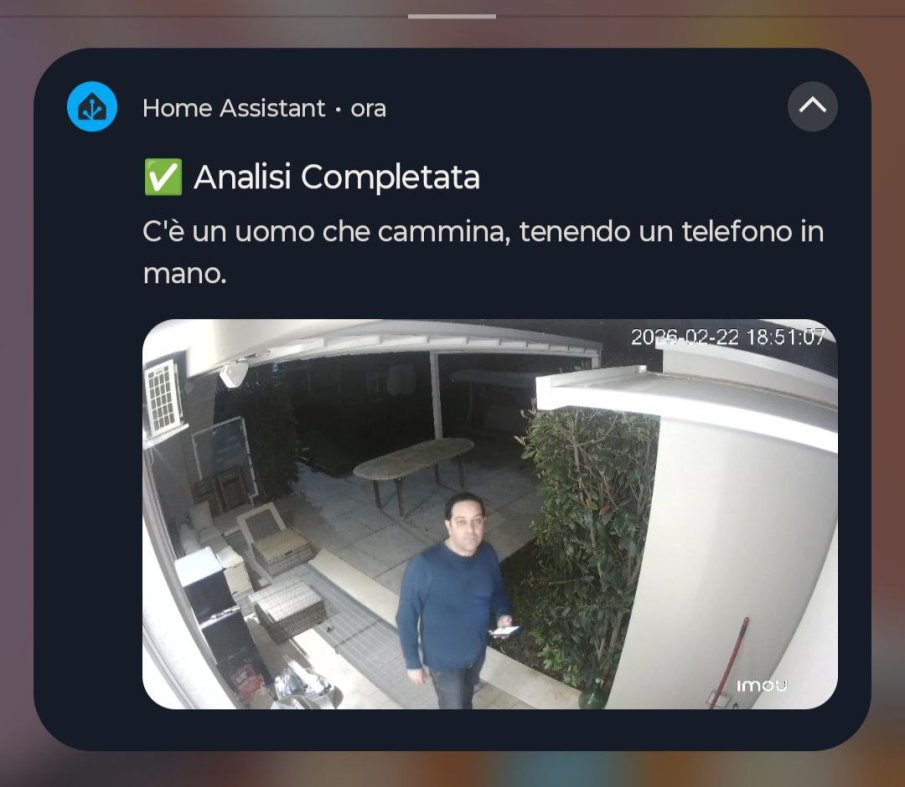
Sovrascrittura Magica (2-6 secondi dopo): Non appena il Mac Mini M4 completa l'analisi, Home Assistant invia una seconda notifica. Poiché usa lo stesso tag, il vostro telefono non suonerà due volte e non creerà un doppione: aggiornerà magicamente e silenziosamente il testo della notifica che state già guardando, inserendo la descrizione dell'IA (es. "Una persona con giacca rossa cammina sul prato").
![Videosorveglianza IA 100 Locale: Home Assistant, Mac Mini M4 e Qwen2.5-VL (Addio Cloud!)]()
Pulizia Falsi Allarmi: Se a far scattare la cam è stata una foglia e l'IA risponde "Nessuno"? L'automazione invia un comando clear_notification che farà letteralmente scomparire dal telefono la notifica di attesa. Pulito, invisibile, perfetto.
Ecco il codice YAML completo. Leggete bene i commenti per capire dove inserire i vostri dati:
alias: "AI Vision: Sicurezza Esterna (Local AI)"
description: Analisi locale con Qwen2.5-VL, Notifiche dinamiche e Retry anti-timeout
mode: single
triggers:
- trigger: state
# 🔴 PERSONALIZZA: Inserisci il sensore di movimento della tua telecamera
entity_id: binary_sensor.tuo_sensore_movimento_giardino
to: "on"
actions:
- action: camera.snapshot
target:
# 🔴 PERSONALIZZA: Inserisci l'entità della tua telecamera
entity_id: camera.tua_telecamera_esterna
data:
# 🔴 PERSONALIZZA: Il percorso dove salvare temporaneamente la foto
filename: /config/www/snap_giardino.jpg
- delay:
seconds: 2
# ==========================================
# 🚀 PRIMA NOTIFICA: ISTANTANEA (CON TAG)
# ==========================================
- action: notify.mobile_app_tuo_smartphone # 🔴 PERSONALIZZA: Il tuo telefono
data:
title: "🚨 Movimento Rilevato"
message: "Scatto catturato. Analisi IA locale in corso... ⏳"
data:
image: /local/snap_giardino.jpg
clickAction: /lovelace/security # 🔴 Opzionale: link alla tua dashboard
# IL TRUCCO MAGICO: Il tag permette di aggiornare questa notifica in seguito
tag: vision_giardino_tag
# ==========================================
# 🧠 INIZIO ANALISI IA (Ciclo di Retry a 3 tentativi)
# ==========================================
- repeat:
count: 3
sequence:
- action: llmvision.image_analyzer
data:
# 🔴 IMPORTANTE: Copia questi parametri esattamente così
store_in_timeline: false
use_memory: false
include_filename: false
target_width: 1280
max_tokens: 3000
generate_title: false
expose_images: false
response_format: text
title_field: title
description_field: description
# 🔴 PERSONALIZZA: Sostituisci con l'ID Provider generato da LLM Vision per Ollama
provider: INSERISCI_QUI_IL_TUO_PROVIDER_ID
message: >-
Rispondi in italiano. Analizza questa immagine. Descrivi brevemente chi c'è
(persona, animale, veicolo) e cosa fa. Se non c'è nulla, rispondi SOLO con "Nessuno".
Max 25 parole.
image_file: /config/www/snap_giardino.jpg
response_variable: ai_resp
continue_on_error: true # Fondamentale per non bloccare lo script in caso di timeout
- choose:
# OPZIONE 1: L'IA ha risposto e c'è qualcosa da segnalare (Diverso da "Nessuno")
- conditions:
- condition: template
value_template: >-
{{ ai_resp is defined and ai_resp.response_text is defined and ai_resp.response_text | length > 2 and 'nessuno' not in ai_resp.response_text.lower() }}
sequence:
# ==========================================
# ✅ SECONDA NOTIFICA: SOVRASCRIVE LA PRIMA
# ==========================================
- action: notify.mobile_app_tuo_smartphone # 🔴 PERSONALIZZA
data:
title: "✅ Analisi Completata"
message: "{{ ai_resp.response_text }}"
data:
image: /local/snap_giardino.jpg
# Usando lo STESSO TAG, il telefono aggiornerà la notifica precedente senza suonare due volte
tag: vision_giardino_tag
- stop: "Rilevamento confermato e notificato."
# OPZIONE 2: L'IA ha risposto, ma è un falso allarme ("Nessuno")
- conditions:
- condition: template
value_template: >-
{{ ai_resp is defined and ai_resp.response_text is defined and ai_resp.response_text | length > 2 and 'nessuno' in ai_resp.response_text.lower() }}
sequence:
# ==========================================
# ❌ FALSO ALLARME: CANCELLA LA NOTIFICA IN ATTESA
# ==========================================
- action: notify.mobile_app_tuo_smartphone # 🔴 PERSONALIZZA
data:
message: clear_notification
data:
tag: vision_giardino_tag
- stop: "Nessun movimento rilevato. Notifica cancellata."
# DEFAULT: Se l'IA va in timeout, aspetta 3 secondi e consuma un nuovo tentativo del ciclo
default:
- delay:
seconds: 3
Conclusioni
Con questo setup, i vostri dati non lasciano mai la vostra LAN. Avete la velocità di un sistema locale supportato dai Tensor Core dell'M4 e l'intelligenza di un LLM di ultima generazione. E la chicca della doppia notifica asincrona restituisce un feeling "Enterprise" che pochissimi sistemi commerciali offrono.
E non finisce qui. Ora che abbiamo un motore visivo fulmineo e affidabile, il prossimo step sarà... il riconoscimento facciale locale dei membri della famiglia. Ma di questo parleremo nel prossimo articolo!
Restiamo Connessi
Se volete ricevere una notifica istantanea ogni volta che pubblico una nuova guida o un aggiornamento su questi progetti (e altri interessanti contenuti), vi invito a iscrivervi al mio Canale Telegram ufficiale:
Iscriviti al Canale Telegram di Vincenzo Caputo
Guarda il video su MissingTech
Come di consueto vi lascio in compagnia del nostro video, correlato a questa guida, direttamente dal nostro canale YouTube MissingTech.
Come sempre, fatemi sapere nei commenti come vi trovate e se avete dubbi sull'implementazione!
Buona visione!
Produrre e aggiornare contenuti su vincenzocaputo.com richiede molto tempo e lavoro. Se il contenuto che hai appena letto è di tuo gradimento e vuoi supportarmi, clicca uno dei link qui sotto per fare una donazione.